I'm a first second-year Ph.D. student at GRASP Lab,
University of Pennsylvania, advised by Prof. René Vidal. I have a broad research
interest in computer vision and graphics. Now I'm focusing on space generation.
I previously was a research intern at Tsinghua University, where I was very fortunate to work with Prof. Yueqi Duan and focused on novel view synthesis.
I received my M.Eng. degree from the College of Artificial Intelligence of Xi'an Jiaotong University, under the supervision of Prof. Shaoyi Du, with the general ranking 1/107+ and the honor of Best Master's Thesis. I received my B.Eng. degree from the School of Software Engineering of Xi'an Jiaotong University, supervised by Prof. Zhiqiang Tian, with the honor of Best Bachelor's Thesis (1/110+).
Previously, I had some great internships at CCVL group of Johns Hopkins University, Shanghai Artificial Intelligence Laboratory, Sensetime Research and Megvii Research.
I support Slow Science but it is really hard for me to practice it now.

Selected Publications

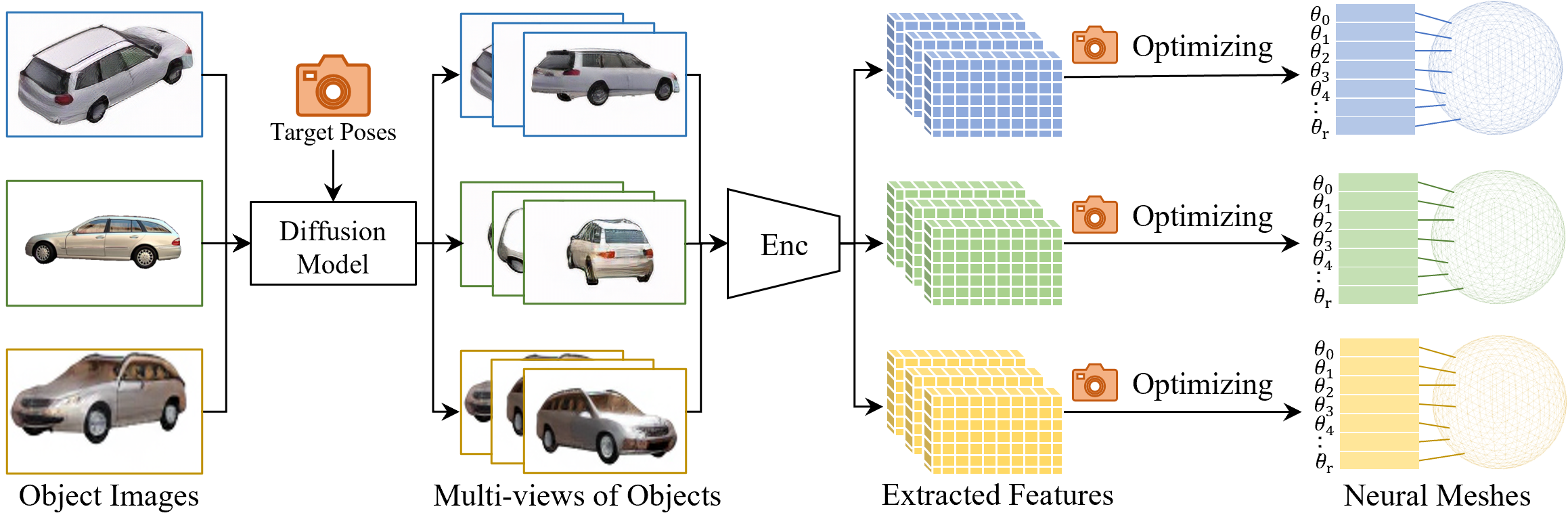
We propose to leverage the power of diffusion model to train a category-level pose estimator without requiring any pose annotations.
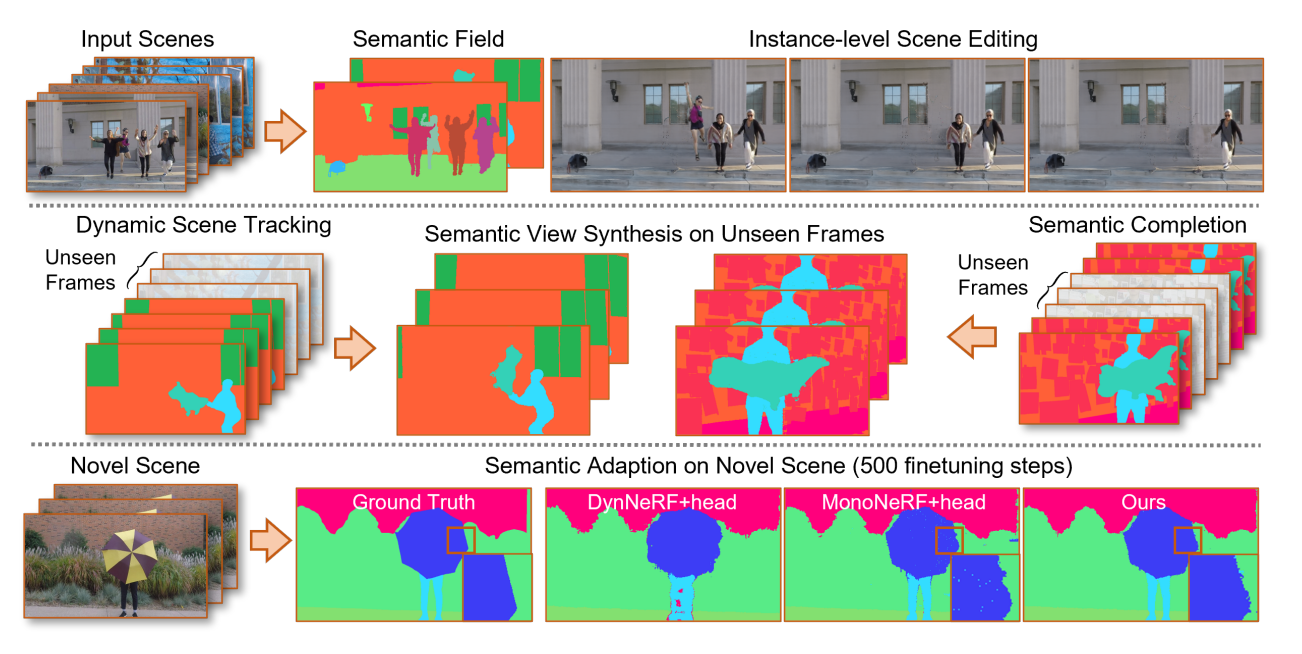
We propose Semantic Flow that builds semantic fields of dynamic scenes from monocular videos.

We propose MonoNeRF for learning a generalizable dynamic radiance field from monocular videos. While independently using 2D local features and optical flows suffers from ambiguity along the ray direction, they provide complementary constraints to jointly learn 3D point features and scene flows.
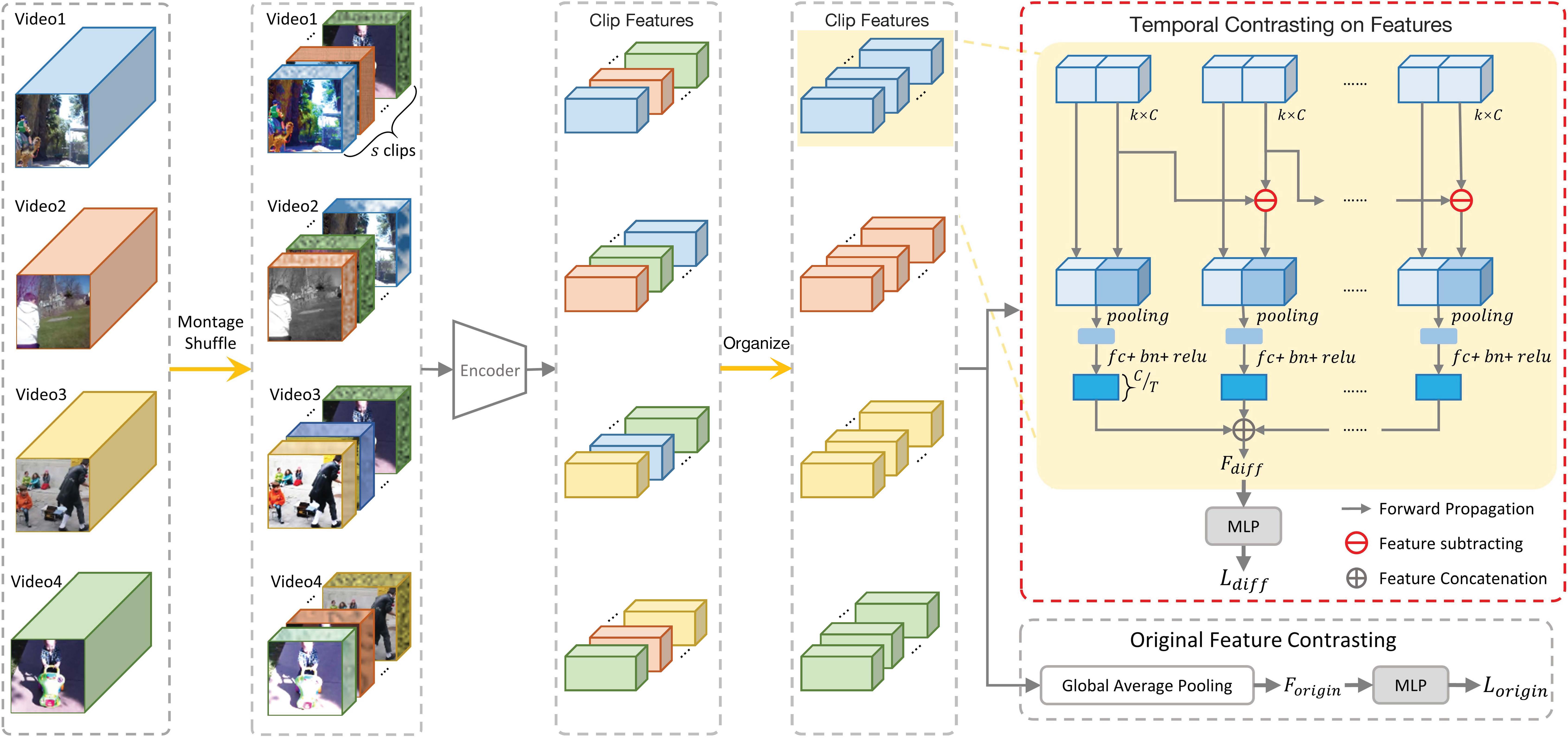
We propose a framework for self-supervised video contrastive learning.
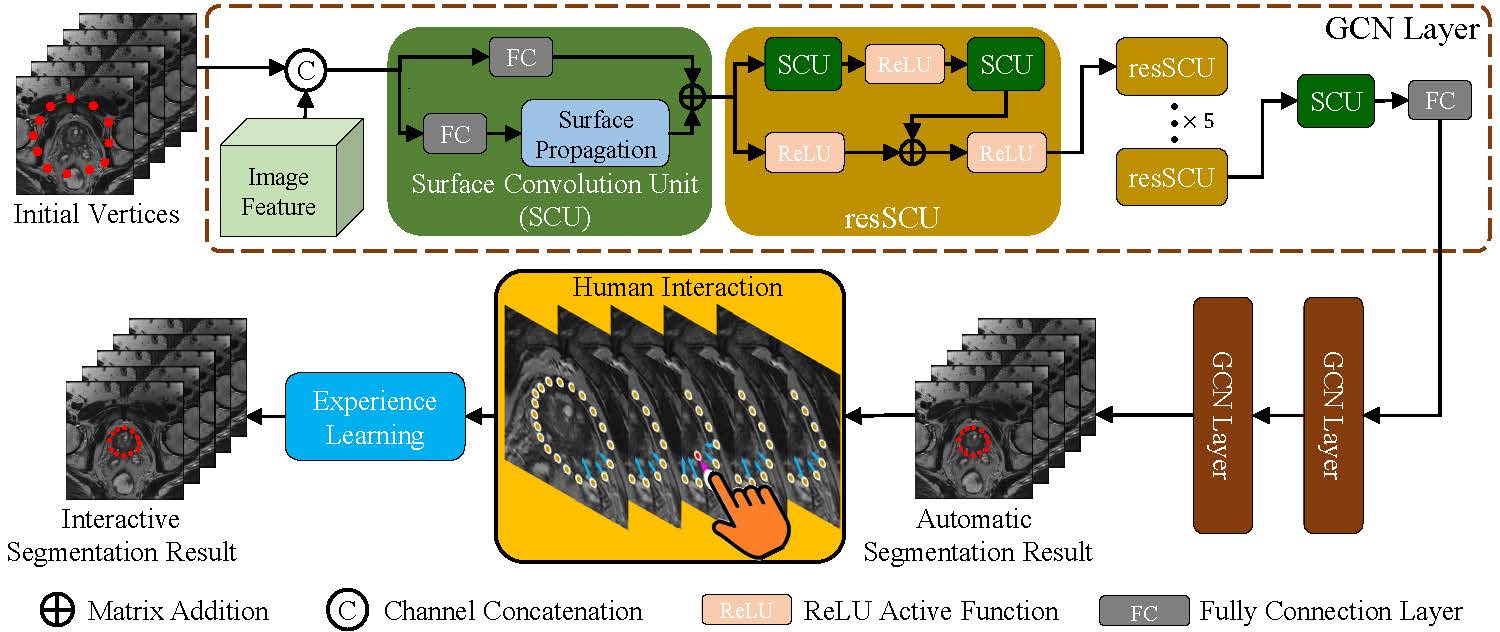
We propose a framework for learning radiologists' experience in medical organ segmentation.
Academic Services
- IEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR) 2023, 2024, 2025, 2026
- IEEE / CVF International Conference on Computer Vision (ICCV) 2025
- ACM Multimedia (ACM MM) 2024, 2025
- Neural Information Processing Systems (NIPS) 2024, 2025
- International Conference on Learning Representations (ICLR) 2025, 2026
- International Conference on Machine Learning (ICML) 2025
- The IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) 2026
- IEEE International Conference on Multimedia & Expo (ICME) 2025
- Chinese Conference on Pattern Recognition and Computer Vision (PRCV) 2024, 2025
- International Conference on Artificial Intelligence and Statistics (AISTATS) 2025, 2026
Honors
- ACCV Best Paper Award Honorable Mention (2/278), 2022
- Top 15 Postgraduates Honorable Mention, Xi'an Jiaotong University (Top 0.1%), 2023
- National Scholarship, Xi'an Jiaotong University (Top 0.1%), 2023
- Xiaomi Special Scholarship, Xiaomi Corp. (Top 0.1%), 2023
- Special Scholarship, Xi'an Jiaotong University (Top 10%), 2022
- Best Bachelor's Thesis, Xi'an Jiaotong University (ranking 1/110+), 2021
- Best Master's Thesis, Xi'an Jiaotong University (ranking 1/107+), 2024
Misc
I am a badminton player. I played badminton at UPenn, XJTU, Tsinghua University, SenseTime Corp., and JHU.
Here are several awards I have won:
- Quarter Final of Badminton Men's Single Contest, SenseTime Corp. 2023
- Semi Final of Freshman Cup Badminton, Faculty of Electronic and Information Engineering, XJTU, 2022
Don't hesitate to contact me if you want to play badminton with me!
I spent a wonderful time on the Model United Nations activities with my closest friends during my undergraduate study. I appreciate and never forget those memories.